เครือค่าย
หน้าในหมวดหมู่ "อำเภอในจังหวัดเลย"
มีบทความ 14 หน้าในหมวดหมู่นี้จากทั้งหมด 14 หน้า รายการที่ปรากฏด้านล่างอาจไม่รวมการแก้ไขล่าสุด
รับ 192.168.1.1/wiki/Communication_Systems/HTTP_Protocol HTTP/1.1
เมื่อเซิร์ฟเวอร์ได้รับคำขอ เซิร์ฟเวอร์จะตอบกลับพร้อมรหัสสถานะที่กำหนดไว้ในมาตรฐาน HTTP ตัวอย่างเช่น:
HTTP/1.1 200 โอเค
HTTP/1.1 404 ไม่พบ
ชื่อโฮสต์คือ www.sjsu.edu/student/tower.gif
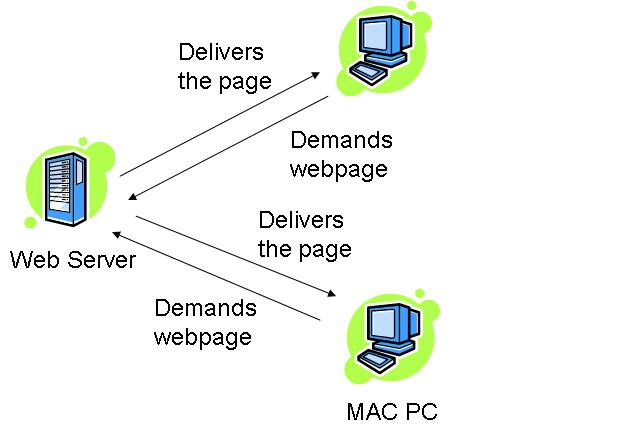


ตัวอย่างต่อไปนี้แสดงถึงเวลาตอบสนอง -

HTTP ใช้ข้อความสองประเภท – 1. ข้อความร้องขอ 2. ข้อความตอบกลับ
รับ /path/to/the/file.html HTTP/1.0
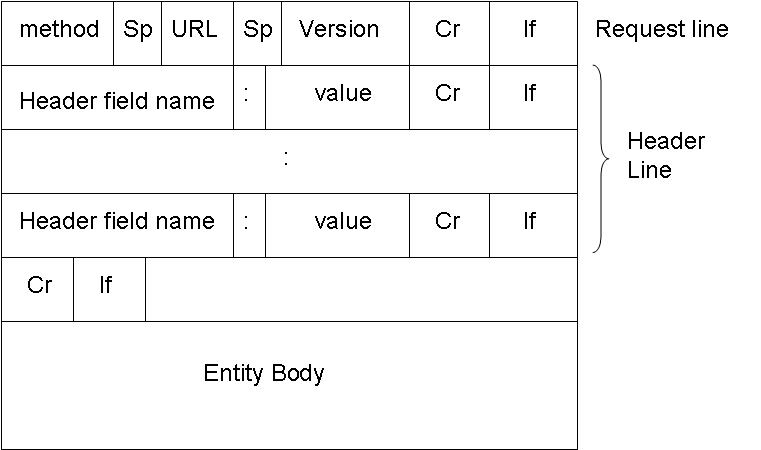
ข้อความคำขอ HTTP: รูปแบบทั่วไป
รูปแบบข้อความคำขอ HTTP แสดงอยู่ด้านล่างนี้:

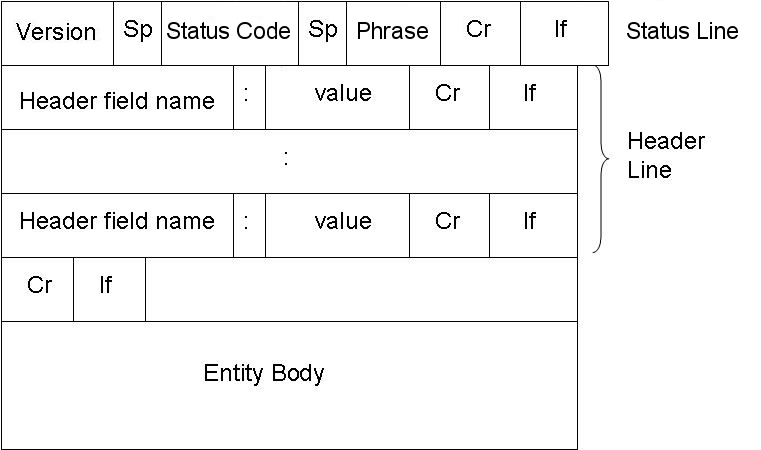
รูปแบบข้อความตอบกลับ HTTP แสดงอยู่ด้านล่างนี้:
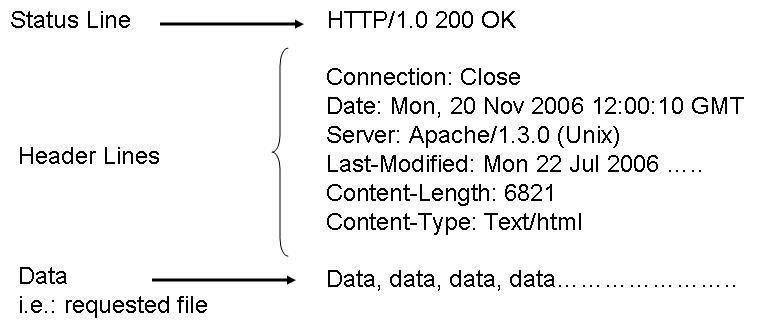
ด้านล่างนี้เป็นรหัสสถานะการตอบสนอง HTTP บางส่วน:
404 ไม่พบ ทรัพยากรที่ร้องขอไม่มีอยู่
1. การรับรองความถูกต้อง 2. คุกกี้
ตัวอย่างทั่วไปคือเมื่อคุณซื้อของออนไลน์ โดยมีการใช้คุกกี้เพื่อติดตามตะกร้าสินค้าของคุณ

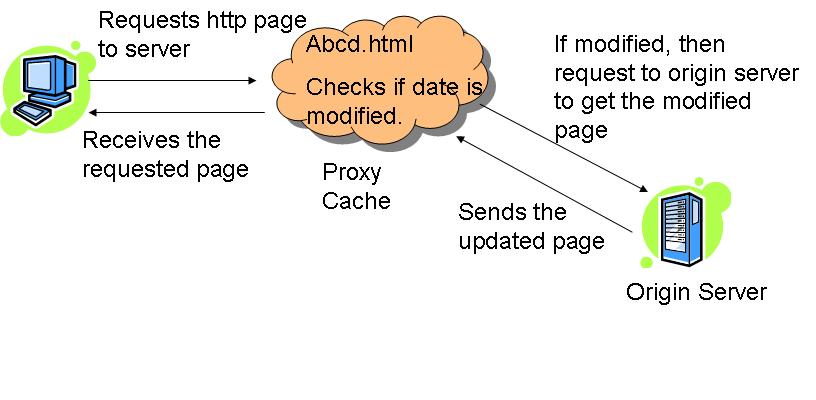
วัตถุประสงค์หลักสองประการของพร็อกซีเซิร์ฟเวอร์คือ:


ความคิดเห็น
แสดงความคิดเห็น